Understanding Spark internals is important because it directly impacts how effectively you can utilize Spark for performance, scalability, and cost efficiency. One key aspect to note in Spark is the concept of lazy evaluation.
Before diving into the main topic, let’s first take a quick look at what actions and transformations are.
In Apache Spark, transformations and actions are the two fundamental types of operations.
Transformations
- operation that defines a new dataset from an existing one.
- Examples – map, filter, flatMap, distinct, groupByKey, join, select, withColumn
Actions
- Actions cause Spark to execute the job according to the transformation lineage.
- They return either a value (to the driver) or write data externally (e.g., HDFS, S3, ADLS).
- Examples – collect, count, first, take, write, show
Lazy evaluation
It means that Spark does not execute transformations (like map, filter, select, etc.) immediately when you call them. Instead, it builds up a logical plan of all the transformations you’ve defined and only executes them when an action (like collect, count, show, save) is triggered.
The obvious question arises: why does Spark wait until an action is triggered, rather than processing each step immediately and then waiting for the next one?
By nature, spark is big data solution and the intention is to solve data intensive problems and optimizing the process is very important compare to traditional data processing systems.
By being lazy what problem it solves?
- The most important advantage is – Spark can look at the entire chain of transformations before running them. This lets it rearrange, combine, or eliminate unnecessary operations.
- Spark has an optimizer called catalyst optimizer. It is the component of the SQL engine responsible for query optimization. It takes the logical query plan and transforms it into the most efficient physical execution plan possible before execution.
- Think of it as Spark’s “query brain” — it looks at what you want, figures out how to get it, and rearranges things so Spark does less work.
- This can be achieved only if spark is lazy, otherwise spark will be executed the way the program written not in optimized way.
- Improved Debugging and Development – In interactive environments such as notebooks (or spark shell), You can construct transformation chains without triggering costly jobs until you are ready. This approach enables rapid iteration during code development.
- By not executing transformations until an action is triggered, Spark saves memory by avoiding unnecessary processing that the application may not require. If the application does require the results, an action can then be added.
The Catalyst Optimizer is a broad topic and will be covered in detail in a separate article. For now, to understand how Spark takes advantage of it, let us walk through a simple example.
Let’s run a quick demo.
Spark Advancing by being lazy with catalyst optimizer
Catalyst is a rule-based optimizer. It takes the logical plan, applies a series of optimization rules, and then converts it into an optimized physical plan. During this entire process, Spark hasn’t even started executing the job yet.
Eliminate distinct
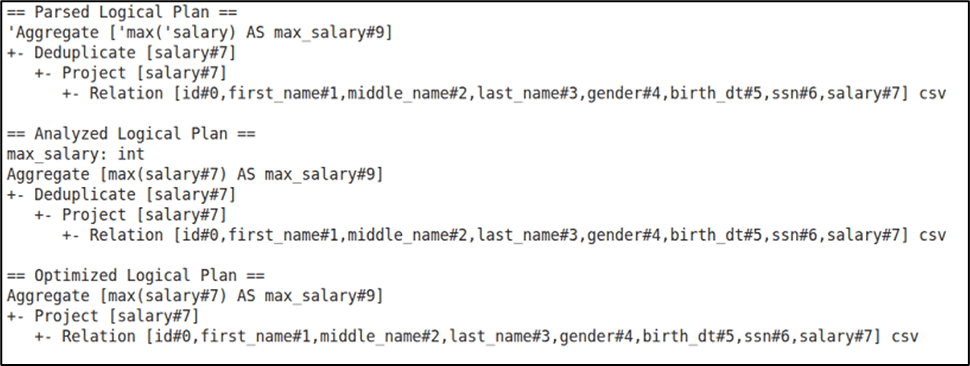
In the example below, the query is written to compute the maximum salary after applying a DISTINCT. However, applying DISTINCT here is meaningless, since calculating the maximum value doesn’t require duplicate elimination.
If an application is programmed in this way, the Catalyst Optimizer steps in and improves the plan by eliminating the unnecessary DISTINCT.

As shown in the image, the initial logical plan includes DISTINCT, but in the optimized physical plan, the redundant operation is removed.
Predicate Push Down
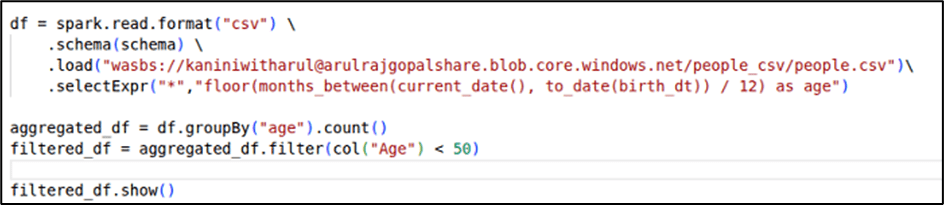
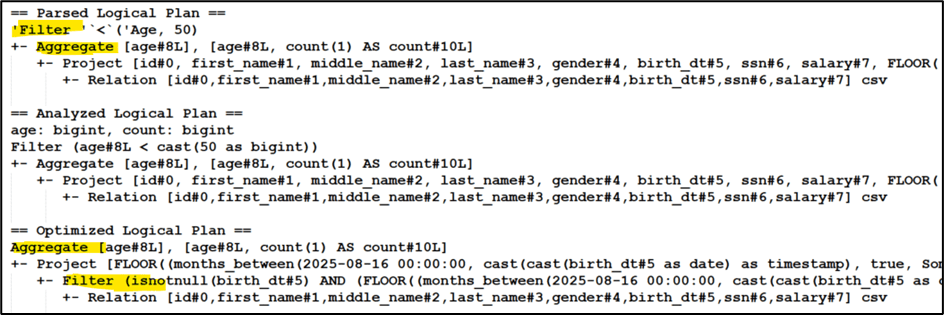
In the example below, the query is written to perform an aggregation (count) by age group and then filter only those records where the age equals 50.
If executed as written, Spark would first aggregate all age groups, and only after that apply the filter to keep age = 50. This means unnecessary computation on data that will eventually be discarded.
This is where the Catalyst Optimizer comes into play. It recognizes the inefficiency, reorders the operations, and pushes the filter before the aggregation. As a result, Spark aggregates only the relevant subset of data, reducing the amount of processing required.
Improved Debugging and Development
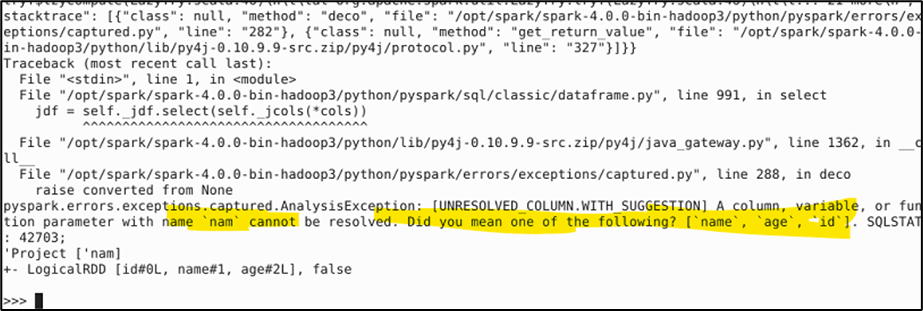
Below is the interactive environment (works in similar way how notebooks work) with Pyspark and DataFrame created.
Now trying to select with wrong column name.
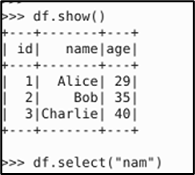
We got the below, which happens without any trigger which makes easy debugging without processing heavy data.
Spark Read is Action or Transformation?
There is a confusion always: is a read operation an action or a transformation?
In reality, a read is neither a pure transformation nor a pure action. It acts as the “source” node in the logical execution plan. While it behaves lazily—making it conceptually closer to a transformation. And only if read and not performing any action, then spark will not execute any job.
In the book “Spark Definitive Guide” Bill says that read is a transformation and it’s a narrow transformation.
Note: If a schema is not explicitly defined during a read operation, Spark will use inferSchema by default. In this case, Spark must scan the entire dataset to determine the schema automatically, which triggers the execution of a Spark job. This means that, in such scenarios, a Spark job can be executed solely through a read operation, without any explicit action being performed.
Conclusion
Spark’s lazy evaluation ensures that transformations are not executed immediately but optimized as a whole before running. With the help of the Catalyst Optimizer, redundant steps are removed, and operations are reordered for efficiency. This approach reduces computation, saves memory, and lowers cost—making Spark both fast and resource-efficient.

Leave a comment