Databricks Spark Declarative Pipelines go beyond simplifying pipeline maintenance—they also address data quality, which is paramount for any data application.
Using expectations, you can define data quality checks that are applied to every record flowing through the pipeline. These checks are typically standard conditions, similar to what you would write in SQL WHERE or HAVING clauses.
Additionally, multiple expectations can be defined on the same dataset, allowing you to enforce several data quality rules in a clean and declarative way.
Types of expectations
- Warn – sends the non-quality record to downstream (default option)
- Fail – when the non-quality record found, it fails the pipeline
- Drop – drops the non-quality records, and sends only quality records to downstream

How to set rules in the SDP & different options for setting it.
Defining rules in python dictionary:

Python syntax to call in notebook:
| dp.expect dp.expect_all | Used to set for warning |
| dp.expect_or_drop dp.expect_all_or_drop | Used to drop invalid records. |
| dp.expect_or_fail dp.expect_all_or_fail | Fail the pipeline, so manual intervention required. |
Let’s try. In this article, I have experimented with different types of expectations.
Source code link
Demoing warn & drop
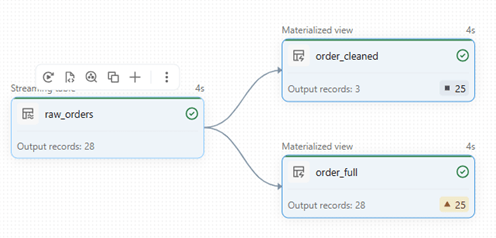
Below is the developed pipeline, where incoming raw data is validated and written into two separate tables.
The order_cleaned table retains only valid (good) records, dropping all invalid ones.
In contrast, order_full processes all records, with a warning message of how many invalid records were encountered as warnings.

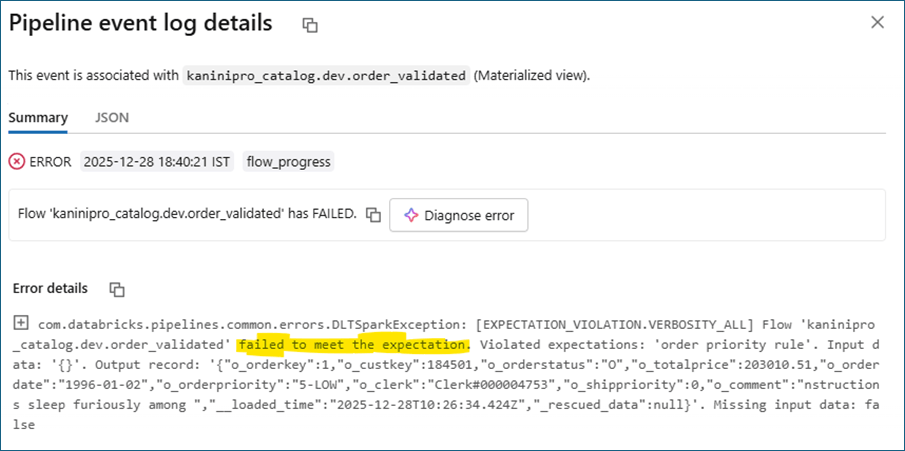
Demoing Fail due to invalid records
Same implementation with a stricter condition.

During execution in SDP, the pipeline failed because the data did not meet the defined expectations. In this scenario, the failure is intentional and acts as a hard guardrail.
Manual intervention is required to understand why the expectation was violated and to perform further analysis and debugging. This represents a use case where no invalid data is ever allowed—invalid records are neither expected nor tolerated, and receiving or producing such data is treated as a critical failure.
I will further explore the expectations capability, how the process more stabilized and reconciled.
Until then!!!
Conclusion
Spark Declarative Pipelines make data quality a first-class concern by enforcing expectations directly in the pipeline, not as an afterthought. Whether you choose to warn, drop, or fail, SDP gives you clear, declarative control to balance data reliability with operational flexibility.
References
https://learn.microsoft.com/en-us/azure/databricks/ldp/expectationshttps://learn.microsoft.com/en-us/azure/databricks/ldp/expectation-patterns

Leave a comment