Spark Declarative Pipelines are designed to simplify the way data processing applications are built by letting engineers work declaratively—you focus on what needs to be produced, and the platform takes care of how it gets executed.
This approach also extends naturally to handling schema evolution. Whether you need to add new columns to the output layer or change the data type of an existing column, the pipeline manages these changes without forcing you to rewrite or tightly control the underlying execution logic.
By abstracting operational complexity, Spark Declarative Pipelines allow teams to adapt to evolving data structures with minimal effort while keeping the focus firmly on business logic.
In this article, we will walk through an example of an existing data processing workflow, explain how downstream systems expect a new schema, and demonstrate how this schema changes can be handled seamlessly using Spark Declarative Pipelines (SDP) and single click full refresh.
Below is the data flow that reads orders & customers data from volume into streaming location and deduping the customer table , then joins both to create the final dataset.

Sdp code for joining the table and loading into final dataset.
Source code link

And below is the queried output and I indicating that order priority field is string.
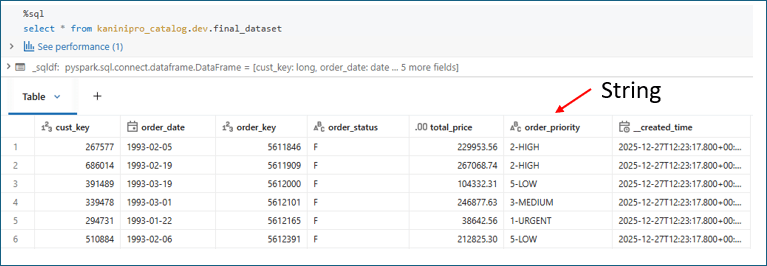
And then, there is a new business requirement, want to change the logic of order priority column which also leads to data type change to int and one more column to be added as mktsegment to support downstream processing.
All the necessary things we have to do are below,
- Change the declaratvie code in SDP
- Do full refresh for the respective tables alone.
Good to go.
Don’t worry about
- Running the alter statement for changing the schema of the tables
- No custom logic to be developed to modify the historical data


Dataset before and after processing—now imagine doing all those transformations without SDP. The sheer effort, manual checks, and endless fixes a data engineer would have to endure . With SDP, it almost sounds like magic.

Conclusion
Spark Declarative Pipelines make schema evolution feel effortless—new columns, logic changes, and type conversions are handled without manual table alterations. By abstracting operational complexity, SDP lets data engineers focus purely on business logic while the platform safely manages execution and state. In short, less plumbing, more impact.

Leave a comment