Incremental load is an efficient approach for moving data into downstream systems by ensuring that only the changes between the previous run and the current run are processed.
However, setting this up is not trivial. There are multiple proven strategies—such as batch-based processing using watermarks to track progress, or streaming pipelines with checkpoints—but all of them require substantial code and system maintenance. In other words, they increase operational overhead. And as I often say, engineering team cost is one of the most expensive components in most projects.
Databricks simplifies this significantly through Spark Declarative Pipelines (SDP).
In my previous article – Getting started with Databricks SDP, I explained how to set up SDP from scratch.
In this article, we will focus on how incremental loads for different SCD types can be implemented quickly and efficiently using SDP.
Before diving in, here are two prerequisites:
- Understand what SCD is and its different types.
- Understand SDP flows, which are a foundational concept. To implement SCD types, we use the Change (Auto CDC) flow type. Other components and flow types will be covered in an upcoming article.
Quick overview of SCD types for readers who may not be familiar with them.
- SCD Type 1: Overwrites old data with new values—no history is kept.
- SCD Type 2: Keeps full history by inserting a new record for each change, usually with effective dates or a version flag.

Prerequisite for the demo.
Source code – https://github.com/ArulrajGopal/kaninipro/tree/main/databricks_SDP_SCD
Create catalog, schema and volume.

Demo
Below is the data preparation code used to prepare the data for initial full load and the next incremental load for the demo from sample dataset of databricks.
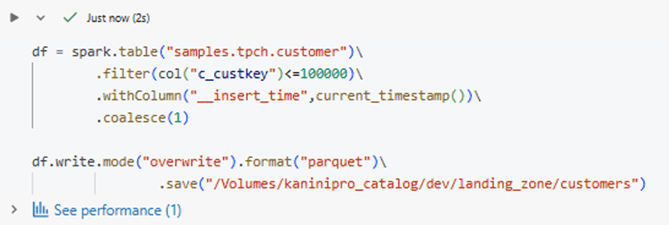
Loading 100K records to the volume where the streaming will start.
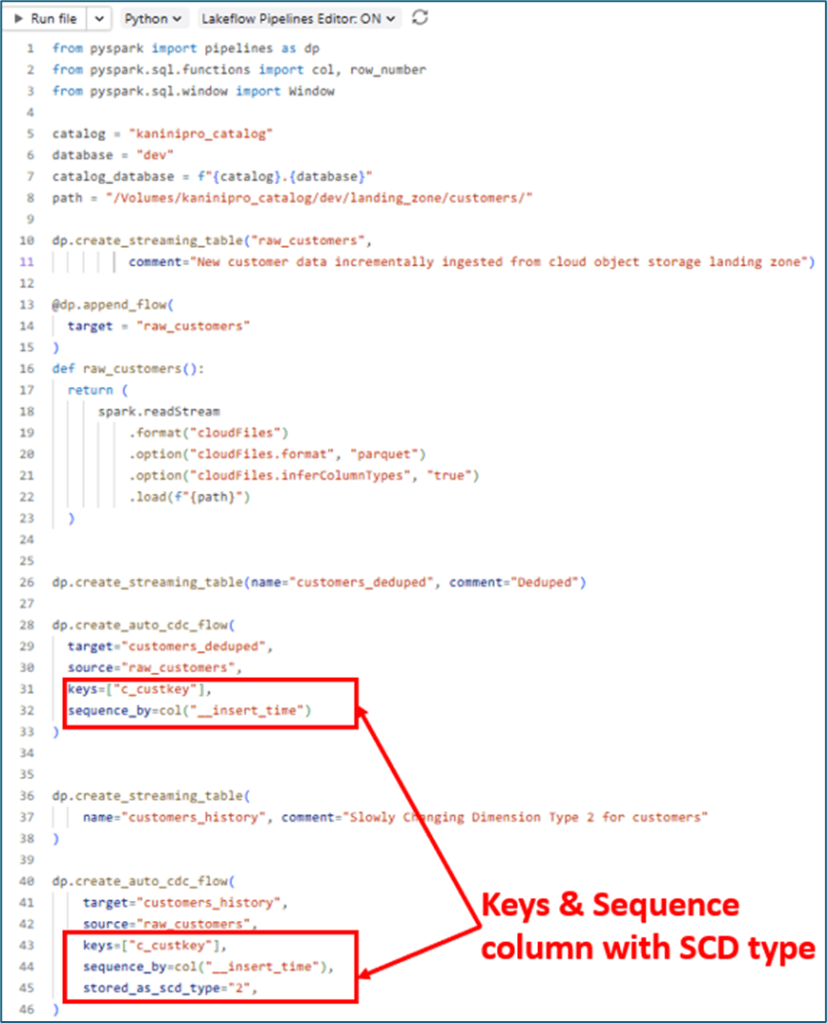
Below is the code that streams data from a volume path and loads it into two tables: customer_deduped (SCD Type 1) and customer_history (SCD Type 2).
It’s important to note that the SCD type, key columns, and sequence_by are vital inputs for this setup. If the SCD type is not explicitly specified, it is treated as Type 1 by default. The key columns and sequence_by fields act as deduplication parameters to determine which record should be processed first when multiple records arrive.
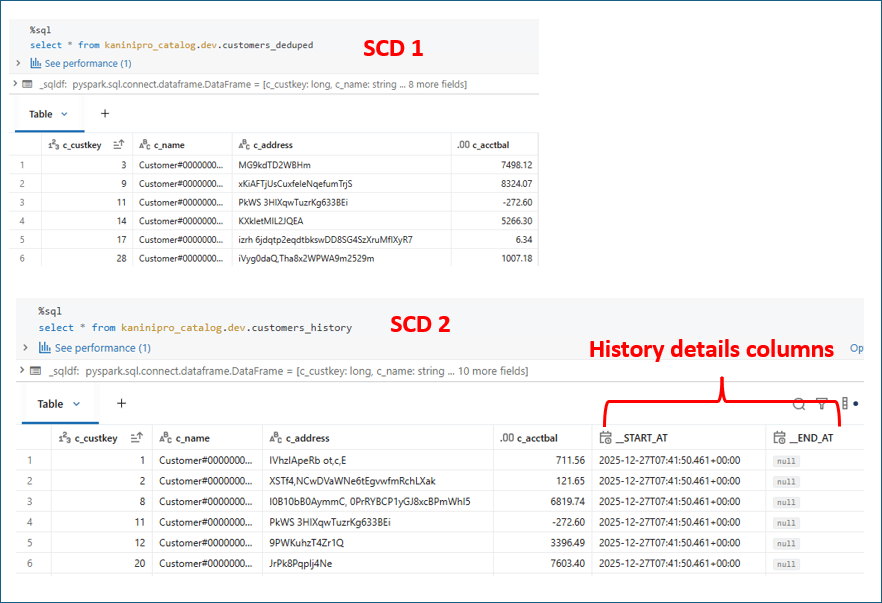
After the initial load, querying both tables shows the expected behaviour. In SCD Type 2, the presence of start_at and end_at columns indicates the validity period of each record, and a NULL end_at represents the currently active version.
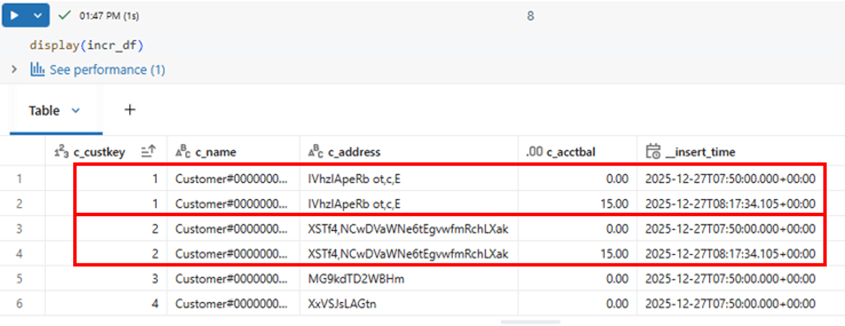
Manipulating few records, and making sure that some of the records sending two times to see how SDP handles with CDC flow.
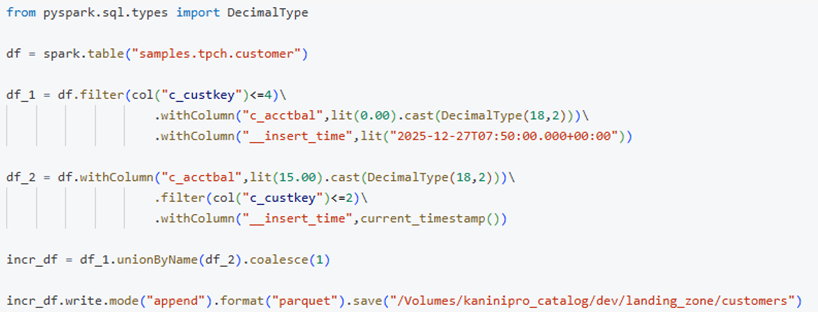
Below is the incoming data which will be used to load incremental and with some duplicates.
Here is the lineage after the incremental run along with performance details. From the raw layer, only incremental records were processed—not a full reload—and both tables were updated accordingly. Since the source contains duplicates, SCD Type 2 processed those records multiple times to correctly capture and maintain the history.
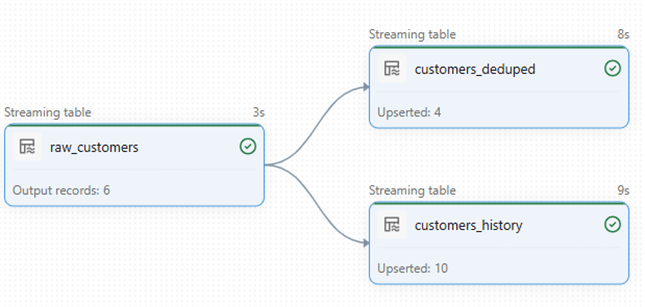

And here is the magic!!!
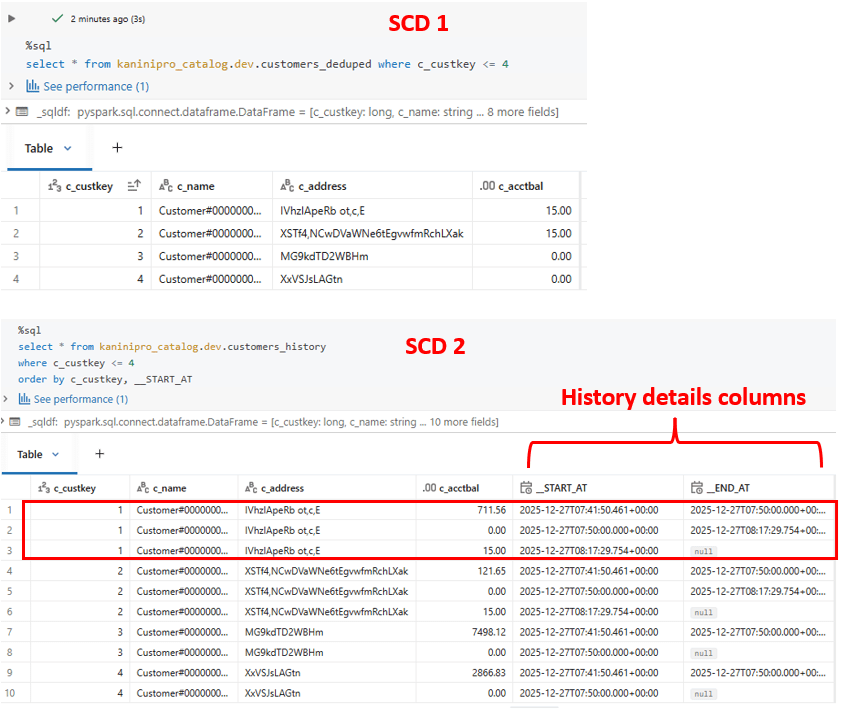
With few lines of code entire SCD type 2 can be setup and tracked is amazing!!!
Conclusion
With Spark Declarative Pipelines, implementing incremental loads with SCD Type 1 and Type 2 becomes remarkably simple and reliable.
SDP abstracts away the complexity of CDC handling, deduplication, and state management, allowing engineers to focus purely on business logic.
With just a few declarative configurations, full history tracking and efficient incremental processing are handled automatically—reducing code, maintenance, and overall engineering cost.
References
https://learn.microsoft.com/en-us/azure/databricks/ldp/tutorial-pipelines

Leave a comment