Spark Declarative Pipelines are one of the flagship capabilities of Databricks, enabling data engineers to focus purely on business logic while abstracting away infrastructure concerns such as cluster provisioning and management etc.
In this article, we will explore how to get started with Spark Declarative Pipelines using Databricks.
Prerequisite –
- Databricks workspace with premium plan & unity catalog enabled. Refer my other article Azure Databricks setup with unitycatalog
- Databricks CLI is installed and authenticated on the client machine;
- Setup the initial code base with databricks bundle, so that it can be deployed through databricks asset bundles and version control can be done through CI/CD. Refer the article to get familiar with bundle initialize and setting up initial code base – Deploying Lakeflow Jobs with Databricks Asset Bundles
Execution –
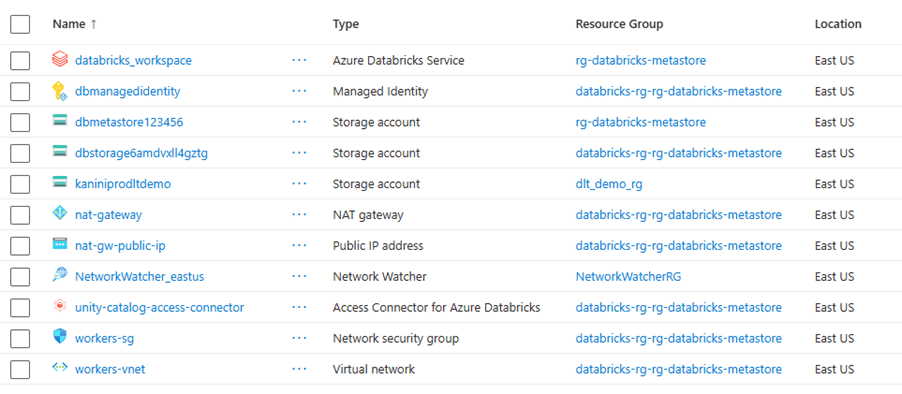
Resources spin up
Databricks CLI authentication

Source code – https://github.com/ArulrajGopal/kaninipro/tree/main/databricks_SDP_startup
Fully developed and deployed pipeline after first run.
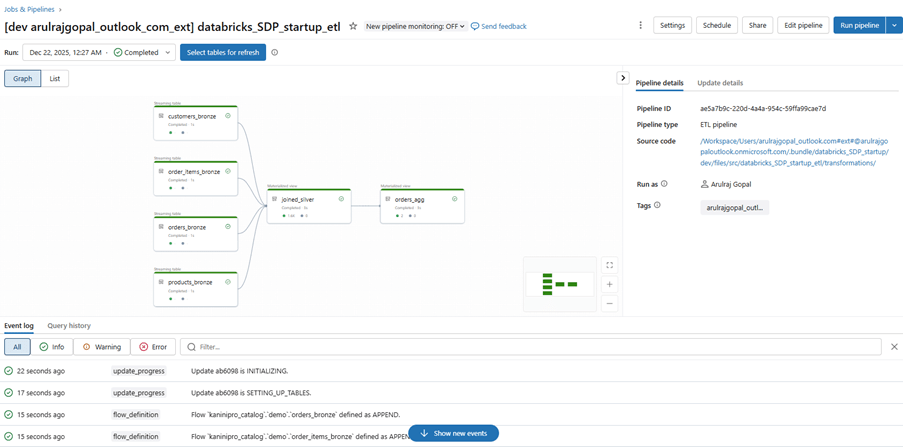
After processing, pipeline graph.

Final output in the materialized view.

With this basic setup of lake-flow declarative pipeline setup is good.
Happy learning!!!

Leave a comment