Clustering is one of the famous techniques in big data systems, especially in lakehouse architecture, It is data layout optimization that arranges data on disk so that, when querying, instead of reading all files in the lakehouse, only a limited number of files will be read using file metadata stats like the min/max of each column’s values stored. This makes data skipping possible.
That can be achieved by sorting the data and storing it. Yes, it sounds simple when we have only one key to order it. What if we have multiple keys?
Still, we can use sort by using both the keys, but let’s illustrate the real problem.
This concept is beautifully explained by Vu Trinh in the article. In this article will try to refresh and experiment it.
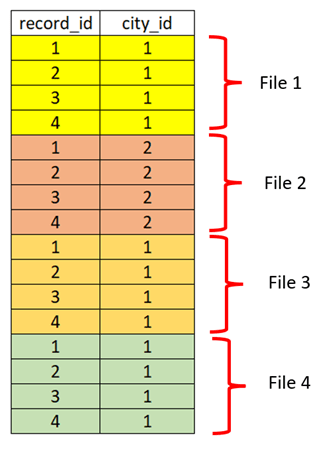
Below is the sample dataset which is sorted by city id and record id. Query the table based on city_id = 2; then only one file will be read. But what if I want to query by record_id = 2? Then it will read all the files and will not be able to do data skipping.
That is where Z-order comes to the rescue.
How does it work?
- Computes a single numeric Z-value for each row using a space-filling curve — by interleaving bits from the hash of each column. With this, data points that are close to each other in the N-dimensional space are grouped.

- Sorts the rows by this Z-value.
- Writes new compacted Parquet files where related rows (close in Z-order) are stored physically close together.
- Z-ordering supported by Delta Lake, Iceberg, or Hudi.
Note: I don’t find any option for Z-ordering while writing data for the first time. So, the data is written first and then optimized later. This adds extra payload to the cluster, but it still makes sense to do so when the data will be read multiple times.
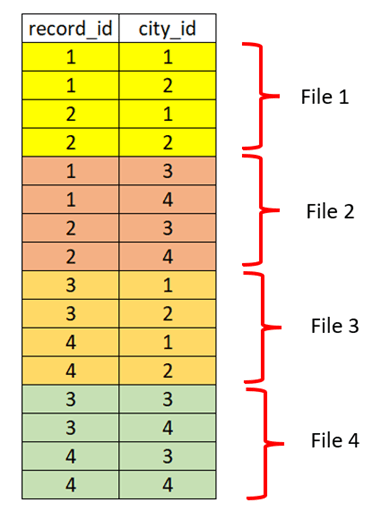
In the same mentioned dataset, in the case of Z-ordering, the data layout will be in the format shown below. With this, city_id = 2 will be read by reading two files, and record_id = 2 will also be read from two files. This is very useful when dealing with large datasets.
Implementation
Here is the source code for below illustration: delta-lake Z-order
Write and optimize

Partial optimizes (it will be useful, when new data coming in as incremental)
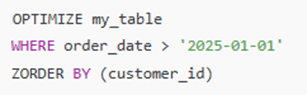
Experiment
With some sample data, with and without Z-order run and results attached below and here is the query used for data prepare and testing Delta-lake Z-order.
Query and result:

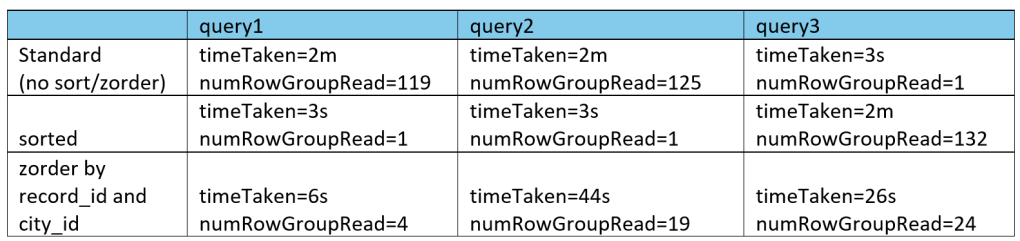
Those who is not aware about what is row group: – A row group in a Parquet file is a horizontal partition of the dataset that stores a subset of rows together. Each row group contains column chunks for all columns, enabling efficient columnar reads and parallel processing.
I explained that in detail in parquet file article.
Conclusion
Z-order clustering optimizes data layout by interleaving bits from multiple columns, keeping related records physically close on disk. This greatly improves query performance through efficient file pruning and reduced data scanning in lakehouse systems.
Reference link
https://delta.io/blog/2023-06-03-delta-lake-z-order/

Leave a comment