When working with massive data, shuffling is one of the costliest operations, and engineers make every effort to reduce it as much as possible. This is achieved through two data-skipping pillars: partitioning and clustering.
Clustering is preferred for high-cardinality field searches, and lakehouse architectures like Delta Lake, Iceberg, and Hudi provide different options such as Z-order, liquid clustering, and ingestion-time clustering. However, in some situations, there is a need to keep the data outside of the lakehouse, such as in simple Parquet tables (probably for downstream streaming).
Bucketing is one of the clustering techniques that uses hashed columns so that, when the table is joined next time, shuffling can be avoided.
Spark bucketing applications
- Mostly used for joins. Pre-shuffle tables for future joins
- Number of buckets should be between 0 and 100000
- The number of partitions on both sides of a join has to be exactly the same
- Bucketing is not allowed at delta tables.
How it works
Spark computes a hash (Murmur3Hash algorithm) of the bucket column value. Rows with the same bucket id are stored together in one file. During joins, Spark can directly map matching buckets, avoiding full data shuffle.
Spark knows whether the table is bucketed or not, by using metastore details.
Formula used in spark to derive bucket id.
| bucket_id = (hash_function(column_value) & Integer.MAX_VALUE) % num_buckets |
Syntax

Experiment
Below Code: spark_bucketing_code
Switched off broadcast and AQE to understand bucketing, otherwise spark will use the smartness and do broadcast join or AQE shuffle read.

Dataframe created using create & written with bucketing.

Performing join on the dataframe which read from tables.
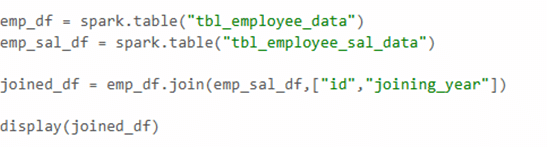
Below is the result of with and without bucketing. It is clear that Exchange (shuffling) can be skipped if rightly bucketed.

Conclusion
Bucketing in Spark minimizes costly shuffles by pre-hashing data into fixed buckets, enabling faster joins. It’s ideal for static Parquet datasets where performance and shuffle avoidance matter most.

Leave a comment