Not every performance gain comes from fancy techniques like broadcasting, partitioning, or caching. Sometimes, the right way of querying makes all the difference — and that’s where strong data skills and a deep understanding of technology fundamentals come in.
Here are some sample scenarios where queries can perform efficiently regardless of the setup:
- Filter column differs from the partition column
- Large datasets deduplication
- Replacing a GROUP BY + JOIN operation with a window function
Note: These discussions primarily apply to OLAP systems.
Filter column differs from the partition column
If your search column isn’t the same as your partition column, don’t go for a full table scan.
- First, select the distinct partition column values that overlap with your search.
- This helps you scan only relevant partitions using the power of columnar storage.
- Then, apply your filter on both the partition key and the search key — so your query scans only limited data, improving performance significantly.
Below is direct and efficient query both are benchmarked using noop
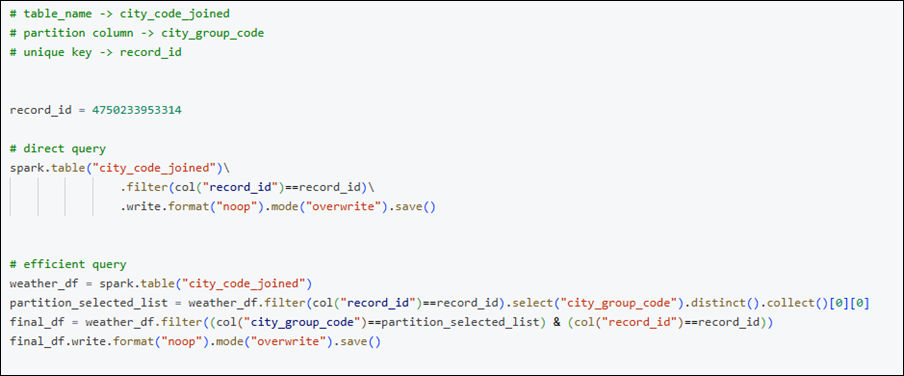
And the result is —
This experiment was conducted on a table with approximately 20 fields. If the number of columns increases, the efficiency will improve even further, as the key factor behind this performance gain is columnar storage.

Large datasets deduplication
In reality, this approach doesn’t improve performance directly — instead, it helps reduce cluster size while achieving the same result.
When deduplicating a large dataset using window functions and ROW_NUMBER, the process consumes significant in-memory resources, leading to larger cluster configurations and higher costs. Since this is a single-stage operation, there’s no option to write intermediate results to a staging table.
That’s why the mentioned logic helps minimize shuffling, use less memory, and reduce overall cost, even if it takes 2–3 times longer compared to running on a larger cluster.
Below direct dedupe query ran with smaller cluster and failed due to heavy shuffling and memory overhead. Cluster size used – single node Standard_F4 8GB 4 Cores
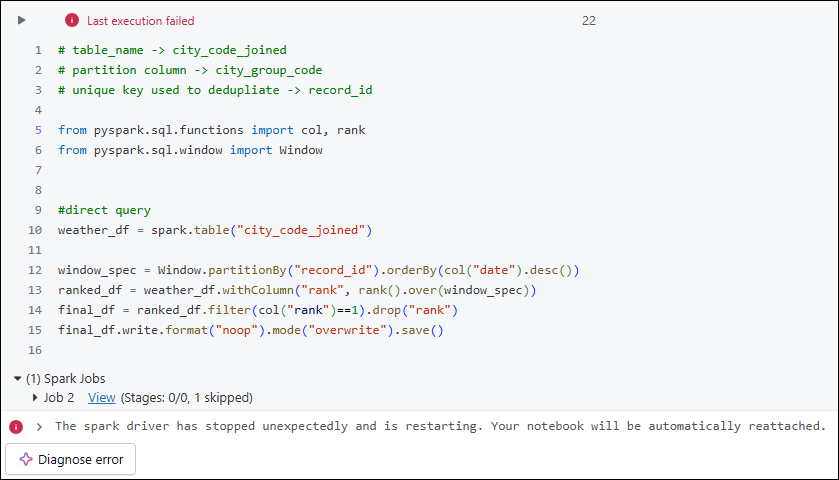
Changed Logic explanation:
- Read the source, add a unique key using a monotonically increasing ID (a narrow transformation), and write the result to a staging location.
- Read from the staging location selecting only the columns required for dedupe, plus the partition key and the derived unique key. This keeps the dedupe data lean and — by leveraging columnar storage — significantly reduces shuffle size.
- Finally, perform an inner join with the staging data where the right-side table is the deduped set and the join keys are the derived unique key plus the partition key; the partition key enables partition pruning.
After changing the logic and running on the same cluster, the job completed in 1h 33 mins. When I doubled the cluster size and ran the direct query (the query mentioned above), it completed in 53 mins.
This shows that the extra I/O between stages added time, but the new logic achieves the result using half the cluster size without doubling runtime. That’s why I describe this approach as a memory-optimized query.

Replacing a GROUP BY + JOIN operation with a window function
In analytics systems, aggregation is one of the most-used operations. Often we need aggregated results along with key values — and in some cases we must preserve non-aggregated columns (or even the aggregated columns themselves) alongside the aggregates.
A common pattern is to aggregate first and then join the results back to the original dataset, but that requires two shuffles. A better approach is to use window functions with aggregate expressions so you can keep both non-aggregated and aggregated fields while avoiding one shuffle.
Note: This technique is most useful when the number of fields is small. If the schema has many columns, perform a proper analysis to decide the best approach before moving to production.


Conclusion
In OLAP systems, true efficiency not only come from advanced optimizations but from smart query design. By aligning filters with partitions, optimizing deduplication through staging logic, and replacing complex joins with window functions, we can achieve significant performance and cost benefits.
These proven techniques emphasize that thoughtful querying is often the most powerful form of optimization.
References

Leave a comment