In Spark, repartition and coalesce are two options used to rebalance DataFrame partitions for better performance and data management.
The key technical differences are shown below:
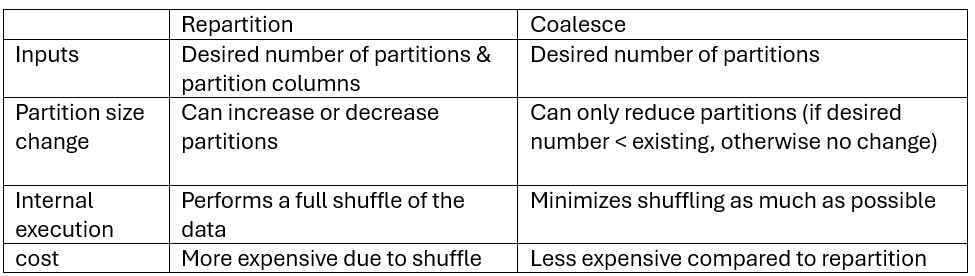
At first glance, coalesce seems more efficient and is often preferred. However, in certain situations repartition can be much more effective.
When to Prefer Coalesce
Coalesce is typically used to reduce the number of partitions with minimal shuffling. It helps align the number of DataFrame partitions with the available cluster cores, which reduces data skew and improves parallelism.
However, the intention of coalesce is only to create even partitions. It doesn’t control how records (based on a key) are distributed across partitions.
If the coalesced DataFrame is later written to storage (i.e., as Parquet files), each file will directly correspond to a partition, but without any consistent ordering or key-based grouping.
As a result, when reading the data back—especially for limited data queries—you may end up triggering a full scan, since the data is not organized by any key.
When to Prefer Repartition
Repartition is better suited when the data will be read multiple times or when you want the records distributed more evenly across partitions (or based on a specific column). This ensures downstream queries will be faster and avoid unnecessary full scans.
Let’s assume we are receiving data in the pattern shown below. Downstream processes may query it using a low-cardinality column (e.g., event_date). If the records are ordered such that each Parquet file contains only one event_date, then a Parquet reader (like Spark) can directly target the relevant file using the metadata (min/max statistics) instead of scanning all files.
Since this data will be read and joined multiple times, avoiding shuffling at the read stage through repartitioning is far more efficient than relying on coalesce, which only minimizes shuffling during writes and transformations before write.

Demo on Repartition preferred scenario
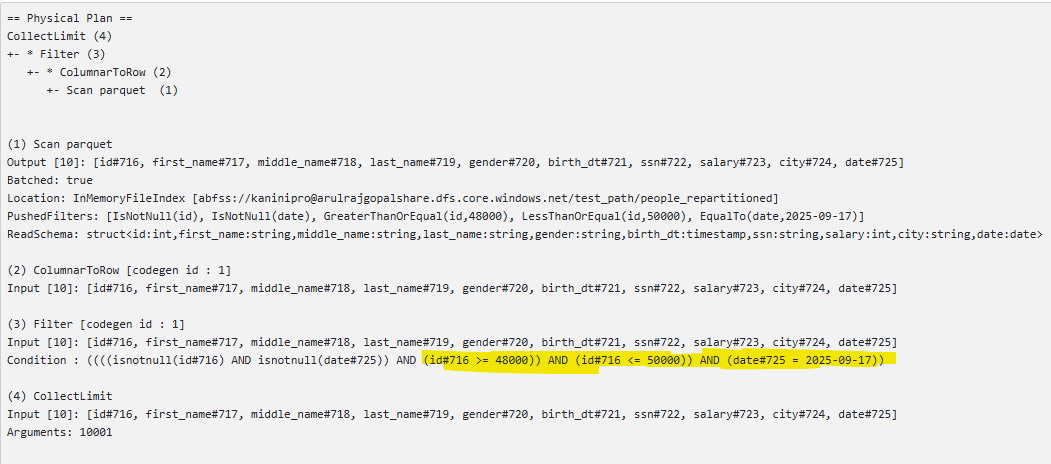
The following PySpark code repartitions the DataFrame based on the date field. As shown in the next image, the data is saved into five Parquet files, corresponding to the five distinct dates present.

Using the code below, the min and max values from each Parquet file were extracted, and they perfectly match the expectation.

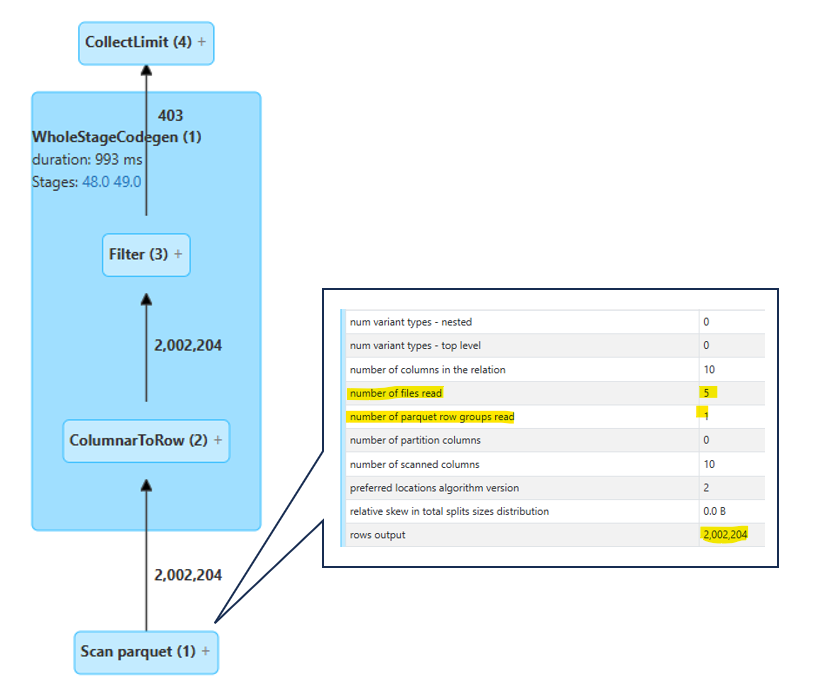
I queried the table and reviewed the execution plan to see how many files and row groups were read. The result shows that only one row group with 2M rows (about 20% of the data) was scanned. This clearly demonstrates that storing the data after repartitioning creates an optimized layout, making reads more efficient—especially in workloads with heavy query activity.

This approach is similar to what Hive-style partitioning does—but with some differences in how it’s applied.
For those unfamiliar, Hive-style partitioning organizes data so that the directory structure reflects the partition column names and their values which helps query engines (like Spark, Athena, or Presto) to infer partition columns directly from the file paths without reading the data itself, which makes partition pruning straightforward.
When to Prefer Repartition over Hive-Style Partitioning
When writing a DataFrame with uneven Spark partitions using Hive-style partitioning, a single Hive partition folder may end up containing many small files—one for each Spark partition. This can quickly lead to the small files problem.
In simpler scenarios, where all records with the same value can comfortably fit into a single Parquet file (and you don’t want the extra metadata overhead of directory structures), repartitioning is often the better choice.
The next obvious question is: What if we need to distribute data evenly based on a high-cardinality column? Hive-style partitioning is definitely not suitable here, since it would create a huge number of folders. That is where repartitioning by range becomes useful.
Repartition by Range
Repartition by range is most suitable for high-cardinality columns, like the id column in our example. We can provide the number of partitions as input so that each partition is distributed without overlap of min/max range in another partition. This makes read efficient, as seen in the previous example.
Below is the Pyspark code and data distribution in parquet file.


Conclusion
Repartition and coalesce serve different purposes in Spark, each with its own trade-offs. Coalesce is ideal for reducing partitions with minimal shuffle, while repartition is better for organizing data for efficient reads.
Choosing between them depends on the workload and how the data will be queried or stored. Repartition by range is especially useful for high-cardinality columns.
Reference
pyspark.sql.DataFrame.repartition — PySpark 4.0.1 documentation pyspark.sql.DataFrame.coalesce — PySpark 4.0.1 documentation
pyspark.sql.DataFrame.repartitionByRange — PySpark 4.0.1 documentation
Happy Learning!!!

Leave a comment