Data integrity and consistency are the foundation of data reliability. Without them, every model, report, or insight becomes a guess at best — and a risk at worst.
Orphan records are a commonly encountered issue in data management, and effectively handling them is crucial to maintaining high-quality, usable datasets. Unlike traditional systems, big data platforms often lack built-in referential integrity constraints, or the architecture of data pipelines may not allow for enforcing such rules.
In these cases, orphan records must be identified and handled programmatically. A frequent cause of orphan records is the asynchronous arrival of related data elements.
The following demonstration illustrates a scenario in which related records arrive at different times and shows how they can be matched and assembled to form a complete, accurate dataset without any missing information.
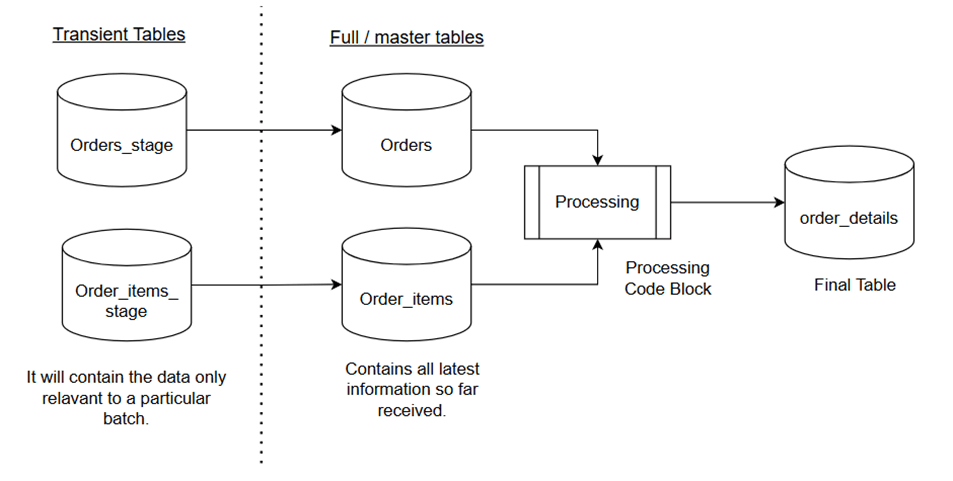
There are ‘orders’ and ‘order_items’ tables that have a one-to-many relationship. However, the corresponding records often arrive at different times.

Orphan records handling Idea & Output
Idea – When a paired record is received from one side but not yet from the other, the first record will wait until its corresponding pair arrives.
Below is the output after processed all three batches.

Flow diagram
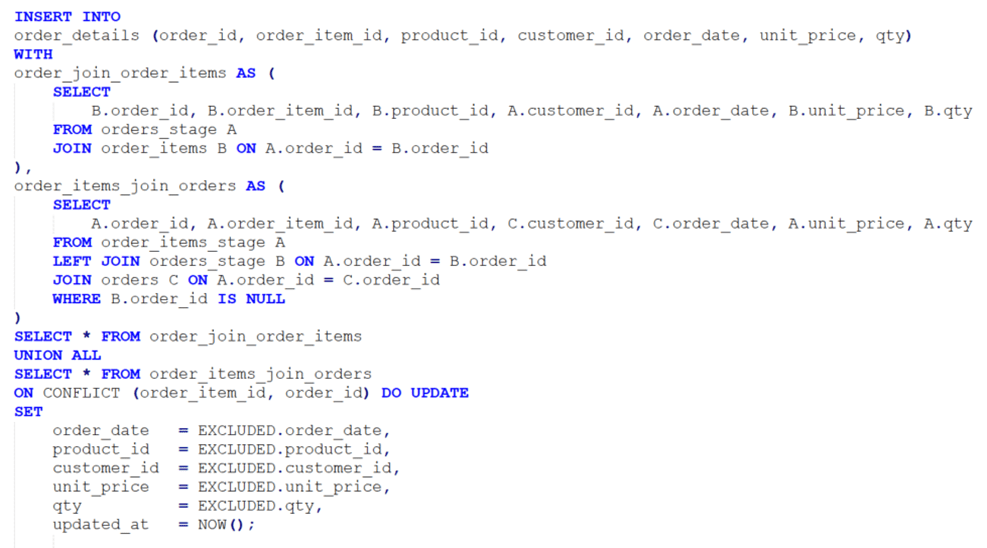
Code block – Stored procedure processing data
In this demo, PostgreSQL stored procedure used.
The repo has the code of this demo —
https://github.com/ArulrajGopal/kaninipro/tree/main/orphan_records_handling
root folder — orphan_records_handling
For initial setup read this file — orphan_records_handling/README.md
Conclusion
With the above explanation, we conclude by emphasizing that data integrity and consistency will be ensured through the application logic. A data-intensive system must maintain these principles to provide valuable business insights and enhance operational efficiency.

Leave a comment