Creating a unique key within a data pipeline is essential for reliably identifying individual records, especially in scenarios where the source dataset lacks a natural primary key and where record traceability is required in later stages of processing.
In distributed processing frameworks like Apache Spark, which operate in-memory and leverage parallel execution, traditional approaches such as window functions for key generation may not be efficient or scalable. Therefore, it is important to evaluate alternative strategies tailored to distributed environments. Let’s explore the available options and their implications.
Different ways to create unique key in spark DataFrame
- Windows & row number
- Using uuid
- Hashing the entire row
- monotonically_increasing_id
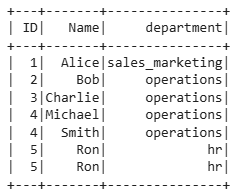
Sample DataFrame
Windows & row number

Below is the physical plan for creating unique key using row number over window spec and it can be clearly understanding that creating unique key brings the data into single partition which kills the performance drastically.
Imagine when the data size is in peta-bytes and brining the entire data into single partition is not efficient.

Using uuid

Creating unique key using uuid is works and it is a lengthy string and causes increase in data size as well difficult in ordering. And it also has some caveats mentioned below,
- python UDFs require data serialization between the JVM and Python via Py4J. This adds overhead and can slow down performance.
- UDF performance is usually lower than using built-in Spark functions
- Spark’s native SQL and DataFrame functions are optimized, whereas UDFs are treated as black boxes and can’t be optimized by Catalyst (the Spark query optimizer)
But still it is good to go with the cases where the key to be globally unique across all runs of the data pipeline job.
Hashing the entire row
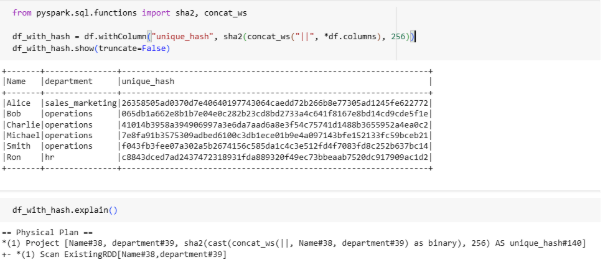
The above code and plan show creating unique key with hashing the entire record and it uses the full advantage of spark parallelism and operations will be completed in narrow transformations.
Using this method, the created key will be unique only when No duplicate is present in data frame otherwise unique key may have duplicates, and to get rid of it, dedupe is required.
There is a risk of collisions (very rare with SHA256) and since it is a lengthy string like uuid data increase data size and spend more energy in ordering.
Monotonically increasing id
The other fine option is to use monotonically increasing id and the below code shows has spark parallelism.

As well, the created column is not lengthy string and much efficient. It doesn’t guarantee order but keys are unique per record.

Notable point is assuming that the data frame has less than 1 billion partitions, and each partition has less than 8 billion records, if not then obviously it will not work.
Conclusion
Selecting an appropriate strategy for generating unique keys within a dataset is critical to ensuring data integrity and effective data governance. The choice of strategy should be guided by a thorough evaluation of the available options, considering their respective advantages and limitations. By understanding the trade-offs, organizations can adopt the most suitable approach that aligns with their architectural requirements.

Leave a comment